Comprehensive Guide to Retriever-Augmented Generation (RAG): Part 2 – Retriever and Generator
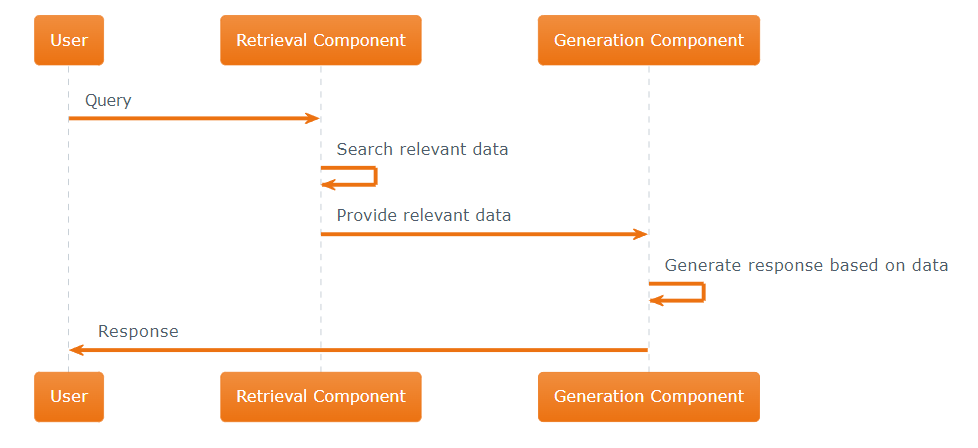
Key Components of Retriever-Augmented Generation (RAG)
Retriever and Generator, the key two components, in Retriever-Augmented Generation (RAG) models are fundamentally designed to enhance the process of generating accurate, relevant, and contextually rich text by combining the strengths of information retrieval and advanced text generation techniques.
The original article introducing Retriever-Augmented Generation (RAG) is titled "Retriever-Augmented Generation for Knowledge-Intensive NLP Tasks" by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela..
Cite as: arXiv:2005.11401 [cs.CL] - https://doi.org/10.48550/arXiv.2005.11401
Retriever
The Retriever component is foundational to the RAG framework, designed to efficiently source the most relevant information from a vast database or knowledge base in response to a query.

The retrieval process in Retriever-Augmented Generation (RAG) systems is a sophisticated mechanism that plays a crucial role in sourcing and selecting data that is most relevant to a given query. This process is foundational for ensuring that the generated text is informative, accurate, and contextually aligned with the query. Here’s a detailed look at how this process works:
Query Understanding
The first step in the retrieval process involves understanding the input query. This typically involves parsing the query into a format that can be processed by the retrieval system. Advanced natural language processing (NLP) techniques, such as tokenization, stemming, and semantic analysis, may be employed to extract the query’s intent and relevant keywords or concepts. Understanding the query accurately is essential for retrieving the most relevant documents.
Vector Representation
A key aspect of modern retrieval systems is the transformation of both queries and documents into vector space representations. This is achieved using techniques like TF-IDF (Term Frequency-Inverse Document Frequency), word embeddings, or more sophisticated sentence embeddings models like BERT (Bidirectional Encoder Representations from Transformers). In this vector space, both the query and the content of the knowledge base are represented as vectors, allowing for the calculation of semantic similarity between them.
Searching the Knowledge Base
Once the query and documents are represented in vector form, the retrieval system searches the knowledge base to find the documents that most closely match the query. This search can be performed using exact match techniques or, more commonly, using approximate nearest neighbor (ANN) search algorithms to efficiently find the top N most similar documents in a large-scale, high-dimensional vector space.
Relevance Scoring
The retrieved documents are then scored based on their relevance to the input query. Relevance scoring can incorporate a variety of factors, including the semantic similarity between the query and document vectors, the presence of query keywords in the documents, and even the contextual relevance based on the document’s metadata (e.g., recency, authority, and credibility of the source).
Selection and Ranking
Based on the relevance scores, the system selects and ranks the documents to be used in the generation process. The top-ranked documents are considered the most relevant and are thus prioritized for information extraction. In some systems, additional filtering criteria may be applied at this stage to ensure the selected documents meet certain quality or relevance thresholds.
Information Extraction
Finally, the relevant information is extracted from the selected documents. This step can involve summarizing the content, extracting specific facts or figures, or simply selecting key passages to be used by the Generator component. The goal is to condense the retrieved data into a format that is most useful for generating an accurate and contextually rich response.
Challenges and Considerations
Balancing Precision and Recall
A key challenge in the retrieval process is balancing precision (ensuring the retrieved documents are relevant) and recall (ensuring no relevant documents are missed). Optimizing this balance is crucial for the effectiveness of the RAG system.
Scalability
As the size of the knowledge base grows, maintaining efficient and accurate retrieval becomes increasingly challenging. Scalable vector search technologies and efficient ANN algorithms are critical for addressing this challenge.
Dynamic Information
For applications where timeliness of information is crucial, the retrieval system must be capable of accessing the most current data, requiring regular updates to the knowledge base.
Generator
The generative process in Retriever-Augmented Generation (RAG) models is a sophisticated operation that synthesizes retrieved information into coherent, contextually rich text. This stage is pivotal for producing high-quality outputs that seamlessly integrate the specific details fetched by the Retriever with the model’s inherent understanding of language and context.

The Generative Process
Preparing Retrieved Data
Once the Retriever component has sourced relevant information, this data is prepared for integration. Preparation might involve summarizing long passages, extracting key facts, or structuring the information in a way that’s easily consumable by the Generator. This step ensures that the Generator works with the most pertinent and concise information, enhancing the efficiency and relevance of the generation process.
Conditioning on Retrieved Data
The Generator, often a large transformer-based language model, receives the prepared data along with the original query. It then conditions its response on this combined input. Conditioning means the model takes into account both the semantic nuances of the query and the specific information from the retrieved data, aiming to generate a response that accurately reflects both. This step is crucial for ensuring that the output is not only relevant to the query but also enriched with the details provided by the retrieved information.
Techniques for Integrating Retrieved Data
Contextual Embeddings
The Generator leverages advanced NLP techniques to create embeddings that represent the semantic and contextual information of both the query and the retrieved data. These embeddings serve as a comprehensive input, helping the model understand the broader context and the specifics of the task at hand.
Attention Mechanisms
Transformer-based models utilize attention mechanisms to weigh the importance of different pieces of input information during the generation process. This means the model can dynamically focus on the most relevant parts of the retrieved data while generating text, ensuring that the output is informationally rich and contextually appropriate.
Sequential Decision-Making
The generation of text is a sequential process, where each word or token is selected based on the current state of the output and the input context. The Generator makes these decisions in a way that optimally combines the original query intent and the specifics of the retrieved information, producing a coherent and logically structured response.
Iterative Refinement
Some RAG models incorporate an iterative refinement process, where initial drafts of the generated text are progressively improved upon. This might involve revisiting the retrieved data for additional insights or adjusting the text to better reflect the combined input. This iterative approach helps in enhancing the fluency and accuracy of the final output.
Challenges and Considerations
Coherence and Consistency
Ensuring that the generated text remains coherent and consistent when integrating information from multiple sources is a significant challenge. The model must effectively synthesize varied pieces of information into a unified whole.
Factuality and Faithfulness
The generated text must accurately reflect the retrieved information. Ensuring the output remains factual and faithful to the sourced data, especially when dealing with complex or nuanced information, is crucial.
Stylistic and Contextual Alignment
The Generator must maintain a writing style and tone that’s appropriate for the query and the intended audience, all while integrating external data that might have its own stylistic nuances.
Interaction Between Retriever and Generator
The interaction between the Retriever and Generator in Retriever-Augmented Generation (RAG) systems is a pivotal aspect that distinguishes RAG from other natural language processing (NLP) models. This dynamic interplay ensures that the generated text is not only contextually relevant but also enriched with information that is accurate and up-to-date.

Dynamic Information Retrieval
The Retriever’s primary function is to fetch relevant information based on the input query. However, its role is not just passive retrieval; it interacts dynamically with the Generator in several ways:
- Contextual Cues: The Retriever uses the initial query and, in some models, feedback from the Generator to understand the context better and refine its search for information.
- Real-Time Retrieval: Unlike static models that rely on pre-encoded knowledge, the Retriever can pull in the most current information from the knowledge base, allowing the Generator to produce responses that reflect the latest data and insights.
Feedback Loops
Some advanced RAG systems implement feedback loops where the Generator’s output influences subsequent retrieval queries:
- Iterative Refinement: The Generator might produce a preliminary response that the Retriever uses to refine its search, aiming to fetch even more relevant or detailed information in subsequent iterations.
- Query Adjustment: The Generator can modify or expand the original query based on the context of the conversation or the task at hand, prompting the Retriever to adjust its search parameters accordingly.
Integrated Response Generation
Once the Retriever provides the relevant information, the Generator begins synthesizing this data into a coherent response. This process involves several key interactions:
- Selective Synthesis: The Generator evaluates the information provided by the Retriever, determining which pieces are most relevant to the query and how best to integrate them into the response.
- Contextual Integration: The Generator uses the context of the query and the retrieved information to produce a response that is not only relevant but also cohesive. It carefully blends the input from the Retriever with its own linguistic capabilities to maintain a natural flow and coherence.
Challenges and Solutions
The interaction between the Retriever and Generator presents unique challenges:
- Information Overload: Ensuring the Generator is not overwhelmed by the volume of information retrieved is crucial. Effective filtering and prioritization mechanisms in the Retriever help manage this.
- Coherence and Relevance: Maintaining coherence in the generated response while accurately reflecting the retrieved information requires sophisticated modeling techniques, including attention mechanisms and contextual embeddings.
Enhancing Model Performance
The synergy between the Retriever and Generator is enhanced through:
- Fine-Tuning: Jointly fine-tuning both components on specific tasks can improve their interaction, leading to better overall performance.
- Customization: Tailoring the interaction mechanisms to suit particular applications or domains can optimize the relevance and quality of the generated content.
The interaction between the Retriever and Generator in RAG systems represents a nuanced balance of dynamic information retrieval and sophisticated text generation. This collaboration enables the production of responses that are not only informative and accurate but also contextually nuanced and engaging, showcasing the advanced capabilities of modern NLP technologies.
This is the second article in our “Comprehensive Guide to Retriever-Augmented Generation (RAG)” series. For those who missed it, you can find the first article at https://templespark.com/comprehensive-guide-to-retriever-augmented-generation-rag-part-1-why-needed/


IslaMartin
What a comprehensive overview.