Generative AI Coding Skill Showdown: ChatGPT 3.5 vs ChatGPT 4 vs Google Gemini vs Bing Copilot
Table of Contents

Genarative AI is a trend
The integration of Generative Artificial Intelligence (Generative AI) into coding and software development has emerged as a pivotal advancement, reshaping the landscape of how code is conceived, developed, and optimized. As Generative AI GPT technologies evolve, they increasingly empower developers to automate routine coding tasks, enhance code quality, and tackle complex problems more efficiently.
Consequently, the growing importance of Generative AI in software development signifies a leap towards more intelligent, adaptable, and efficient programming methodologies, heralding a new era of innovation and creativity in the tech industry.
We use the same prompt across all GPTs: Write the Python code to train a linear regression model using Scikit-Learn.
ChatGPT 3.5
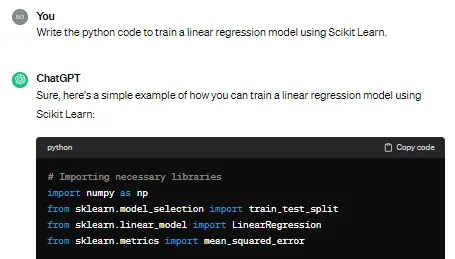
Here are the response from ChatGPT 3.5:
# Importing necessary libraries
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Sample data - you should replace this with your own dataset
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 5, 4, 5])
# Splitting the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Creating a linear regression model
model = LinearRegression()
# Training the model
model.fit(X_train, y_train)
# Making predictions on the testing set
y_pred = model.predict(X_test)
# Evaluating the model
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
# Printing the coefficients
print("Coefficients:", model.coef_)
print("Intercept:", model.intercept_)
Besides the above source code, it also gives the explanation of the code
In this code:
. We import the necessary libraries from Scikit Learn.
. We create some sample data X and y. Replace this with your own dataset.
. We split the data into training and testing sets using train_test_split.
. We create a linear regression model using LinearRegression.
. We train the model using the training data.
. We make predictions on the testing data.
. We evaluate the model using mean squared error.
. Finally, we print the coefficients of the model.Save the source code to chat3.5.py then run it:
$ python3 chatgpt3.5.py
Mean Squared Error: 0.7346938775510206
Coefficients: [0.68571429]
Intercept: 1.7714285714285714ChatGPT 4
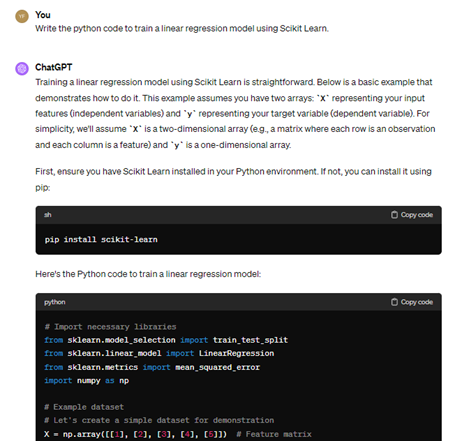
At the onset of the response, ChatGPT 4 offers an explanation of the requirements based on the prompt, along with the assumption that you may require the installation of the scikit-learn package if it’s not already installed. Following that, you’ll encounter the Python source code.
# Import necessary libraries
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
import numpy as np
# Example dataset
# Let's create a simple dataset for demonstration
X = np.array([[1], [2], [3], [4], [5]]) # Feature matrix
y = np.array([2, 4, 5, 4, 5]) # Target variable
# Splitting dataset into training and testing set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Creating a linear regression model
model = LinearRegression()
# Fitting the model with training data
model.fit(X_train, y_train)
# Predicting the Test set results
y_pred = model.predict(X_test)
# Calculating the mean squared error to evaluate the model
mse = mean_squared_error(y_test, y_pred)
print(f"Model Coefficients: {model.coef_}")
print(f"Model Intercept: {model.intercept_}")
print(f"Mean Squared Error: {mse}")Same as ChatGPT3.5, besides the above source code, it also gives the explanation of the code.
This code snippet does the following:
. Imports necessary libraries and modules.
. Creates an example dataset (X and y).
. Splits the dataset into a training set and a testing set.
. Initializes the LinearRegression model.
. Fits the model using the training data.
. Makes predictions on the testing data.
. Evaluates the model by calculating the mean squared error between the predicted and actual values.
Remember, this is a basic example. The complexity can increase based on the nature of your dataset and the specific requirements of your linear regression analysis, such as feature scaling, handling categorical variables, and more.Save the source code to chat4.py then run it:
$ python3 chatgpt4.py
Model Coefficients: [0.68571429]
Model Intercept: 1.7714285714285714
Mean Squared Error: 0.7346938775510206Google Gemini
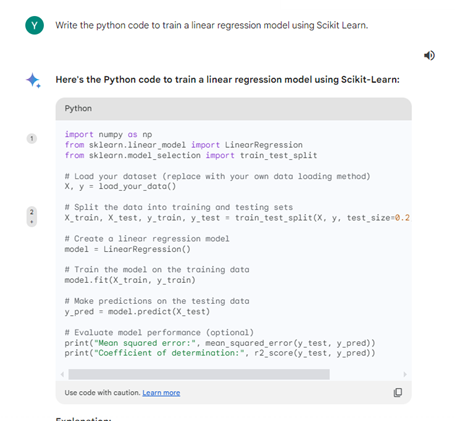
In contrast to ChatGPT 3.5 and 4, Google Gemini offers guidance on the methodology and process for conducting linear regression, rather than providing executable code. Here are the source code from Google Gemini:
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# Load your dataset (replace with your own data loading method)
X, y = load_your_data()
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create a linear regression model
model = LinearRegression()
# Train the model on the training data
model.fit(X_train, y_train)
# Make predictions on the testing data
y_pred = model.predict(X_test)
# Evaluate model performance (optional)
print("Mean squared error:", mean_squared_error(y_test, y_pred))
print("Coefficient of determination:", r2_score(y_test, y_pred))Following the source code, Google Gemini also includes explanations along with links to the referenced sources.
Explanation:
1. Import necessary libraries:
. numpy for numerical computations and array manipulation.
. sklearn.linear_model for the LinearRegression class.
. sklearn.model_selection for splitting data into training and testing sets.
2. Load your data:
. Replace load_your_data() with your actual data loading method, ensuring X contains features and y contains target values.
3. Split data:
. Divide data into training (80%) and testing (20%) sets using train_test_split.
. random_state=42 ensures reproducibility of results.
4. Create model:
. Instantiate a LinearRegression object to represent the model.
5. Train model:
. Fit the model to the training data using model.fit(X_train, y_train).
6. Make predictions:
. Use model.predict(X_test) to predict target values for the testing data.
7.Evaluate performance (optional):
. Calculate metrics like mean squared error and coefficient of determination to assess model accuracy.
Remember:
. Adapt data loading based on your specific dataset format.
. Explore model hyperparameter tuning for potential performance improvements.
. Consider feature scaling or normalization if necessary.
Sources
1. top10livechat.com/how-to-create-a-pltv-model/
2. www.cliffsnotes.com/tutors-problems/Python-Programming/47943149--Project-Instructions-1-Choose-the-Data-set-and-get-instructor/
3. karan-bhatti.medium.com/this-is-what-chatgpt-cant-do-c1f8277bd3a9?source=user_profile---------0----------------------------Bing Copilot
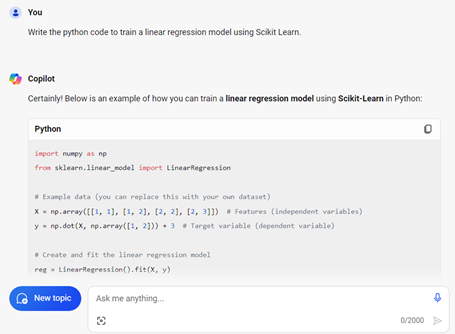
Here are the response from Bing Copilot:
import numpy as np
from sklearn.linear_model import LinearRegression
# Example data (you can replace this with your own dataset)
X = np.array([[1, 1], [1, 2], [2, 2], [2, 3]]) # Features (independent variables)
y = np.dot(X, np.array([1, 2])) + 3 # Target variable (dependent variable)
# Create and fit the linear regression model
reg = LinearRegression().fit(X, y)
# Model evaluation
r_squared = reg.score(X, y)
coefficients = reg.coef_
intercept = reg.intercept_
# Make predictions
new_data_point = np.array([[3, 5]])
predicted_value = reg.predict(new_data_point)
print(f"R-squared value: {r_squared:.2f}")
print(f"Coefficients: {coefficients}")
print(f"Intercept: {intercept:.2f}")
print(f"Predicted value for new data point: {predicted_value[0]:.2f}")Same as Google Gemini, Bing Copilot also provides the explanation along with the reference sources.
In this example:
. X represents the features (input variables).
. y represents the target variable (output).
. The model is trained using the fit() method.
. You can replace the example data with your own dataset to build a linear regression model specific to your problem.
Remember to preprocess your data, split it into training and testing sets, and handle any other necessary steps before training your model. Happy coding! 🚀
Learn more
1. scikit-learn.org
2. stackabuse.com
3. educative.io
4. freecodecamp.orgSave the source code to bing_copilot.py then run it:
$ python3 bing_copilot.py
R-squared value: 1.00
Coefficients: [1. 2.]
Intercept: 3.00
Predicted value for new data point: 16.00Comparative Analyses
You will see the comparative analyses in detail at:



Leave a Reply